



Web crawlers are special applications used to create a copy of all the visited web pages for later processing. They are mainly used for indexing websites to facilitate web search engines but are also used for web archiving, web mining and web monitoring. The basic idea of web crawling is simple: given a set of starting URLs, a crawler downloads all the web pages addressed by the URLs, extracts the hyperlinks contained in the pages, and iteratively downloads the web pages addressed by these hyperlinks. The data collection service to specifically crawl Dark Web sites requires a set of initialisation steps. These include the instantiation services, the proxies and the set-up of a keywords list for targeted look-ups to eliminate the search space in the Dark Web to the concepts which refer to cybersecurity incidents (i.e. hacks, SQL injection, DDoS attacks, etc.), email accounts (i.e. pawned email accounts for breached corporate data, job titles, names, phone numbers, physical addresses, social media profiles, etc.), an organisations’ leaked corporate information and their email servers (i.e. blacklisted email servers or blocked web services). The data migration, harmonisation and linkage services include a set of modules to store, harmonise and link the collected data with related cybersecurity concepts and ontologies. After the process of collecting the data from the Dark Web sites, we store and index them through Elasticsearch. When we retrieve the HTML page, we convert the raw HTML text to cleaned text that contains all the HTML content and it is used as the input for the TFIDF Vectorizer. After the data collection and harmonisation, we perform some text and graph analytics by using state-of-the-art Machine Learning algorithms, such as clustering. The intuition is to group the HTML pages that we collect based on their content similarity, monitor the critical score by means of top k queries of the cybersecurity terms frequency detected in the pages, as well as the way the URLs are linked in a concept graph map. To ease user’s interpretability over the text and graph analytics, we expose the back-end APIs to intuitive visualization charts. The purpose of collecting these web data sources is to extract useful information that can be visualised to report about illegal trading of breached data in marketplaces, blacklisted email servers and news about the corporate rumour of small enterprises found in the Dark Web sites. The pie visualization chart has been chosen to indicate by means of percentage which keywords have appeared more in the Dark Web pages with content relative to cyber-attacks. For instance, hack, malware, and inject are the keywords with the greatest instances in our data collection, but at the same time they are very generic. Other documents including phishing, trojan or DDoS contain much focused information about cybersecurity incidents with however fewer instances.
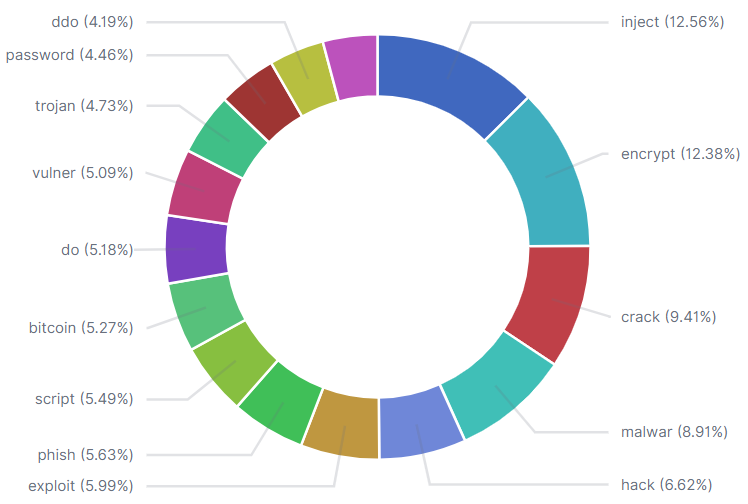
Percentage of Cyber-concepts in Texts
The root URLs with the criticality score of the keywords/cyber-concepts that are found in a heatmap can be also visualised. The criticality score per keyword within each URL is computed according to its category (e.g., CYBER_ATTACKS vs. ALIANSES) and the number of instances found. By using these two features, we can distinguish URLs that may contain critical information, such as breached data, preparation/call for an attack, etc. Also, we use these features to highlight and extract the most suspicious URLs, in order to create a new seed of URLs for new and more focused search.
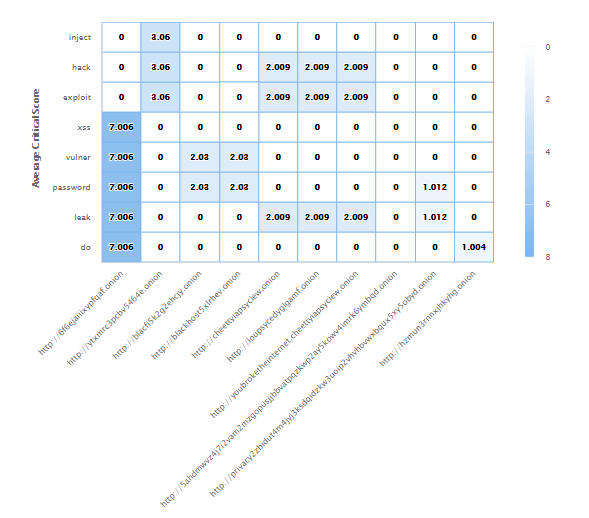
Heatmap Score of URL vs Cyber-concepts
The connections between keywords in our collection are also illustrated as a graph. We used statistical analysis (i.e., “significant text” query from Elasticsearch) for finding hidden connections between keywords. This means that some concepts are related in our data collection. We use sampling to find the keywords connections. For example, the graph visualization shows that “csrf” is one of several terms strongly associated with “backdoor” or “xss”. It only occurs in few documents in our index and therefore most of the documents also contain “backdoor” and “xss” results. That suggests a “significant” word.
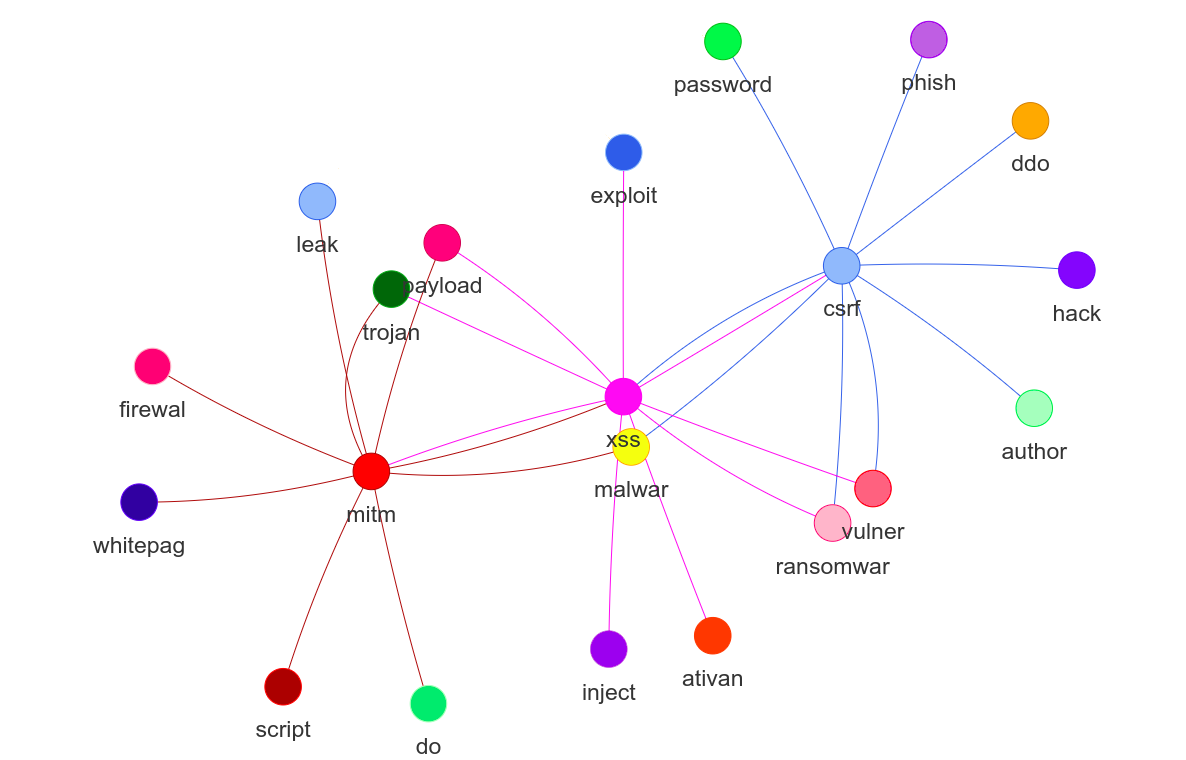
Graph visualization of significant terms interrelated in the Dark Web sites
Document clustering depicts the top-k words of each cluster. We conclude that illegal or inappropriate content are grouped together, the cyber-incidents are grouped within the CYBER_ATTACKS category, while documents without any cyber-concept form their own cluster setting apart irrelevant concepts compared to our context.
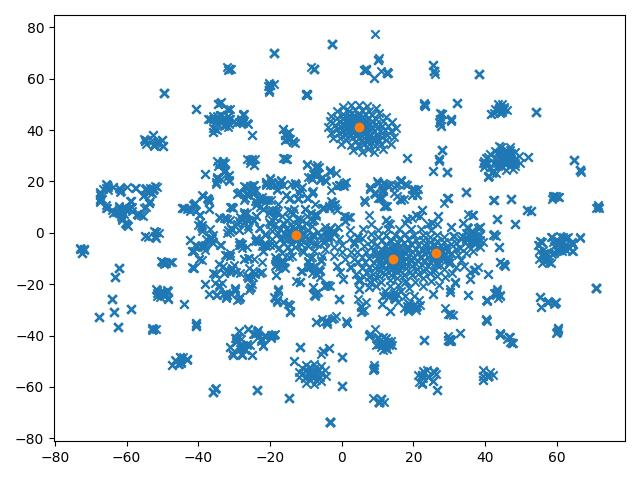
Clusters of Dark Web documents based on their content
